Building CUDAmath Part 2: Optimizing the Matrix Multiplication Kernel
This is a short article explaining a few more optimizations of the Matmul kernel. In the previous article, we left off with coalescing access to the global memory. Now the next step is to use the shared memory, present within each block.
Copying to the Shared Memory
Each block has access to a shared memory location instead of accessing the global memory to compute each cell. We copy a chunk of the input matrices to the shared memory and then perform the dot product by accessing the shared memory.
(Note: I have simplified the code by assuming square matrices)
__global__ void sgemm_shared_mem(float *a, float *b, float *c, int m, int n, int common_dim, float alpha, float beta){
// specifying the dimension of the chunk copied
const uint BlockSize = 32;
const uint out_COL = blockIdx.x;
const uint out_ROW = blockIdx.y;
// Defining the Shared Memory
__shared__ float a_shared[BlockSize * BlockSize];
__shared__ float b_shared[BlockSize * BlockSize];
const uint local_COL = threadIdx.x % BlockSize;
const uint local_ROW = threadIdx.x / BlockSize;
// Moving the Pointers to the Starting Point.
a += out_ROW * BlockSize * common_dim;
b += BlockSize * out_COL;
c += out_ROW * BlockSize * n + BlockSize * out_COL;
float sum = 0.0;
for (int i = 0; i < common_dim; i += BlockSize){
// Copying to Shared Memory
a_shared[local_ROW * BlockSize + local_COL] = a[local_ROW * common_dim + local_COL];
b_shared[local_ROW * BlockSize + local_COL] = b[local_ROW * n + local_COL];
__syncthreads();
a += BlockSize;
b += BlockSize * n;
// Multiplying the elements
for (int j = 0; j < BlockSize; ++j){
sum += a_shared[local_ROW * BlockSize + j] * b_shared[j * BlockSize + local_COL];
}
__syncthreads();
}
c[local_ROW * n + local_COL] = alpha * sum + beta * c[local_ROW * n + local_COL];
}Using the above kernel, we could multiply two 256x256 under 0.9 seconds, in my system.
Now how are we going to optimize this further?
Kernel 1D Blocktiling
We have to reduce our access to the shared memory. We can achieve that by having a thread compute more than a single output element. We can have it compute a column of output elements, this would make it so that we use the thread-local memory, instead of accessing the shared memory.
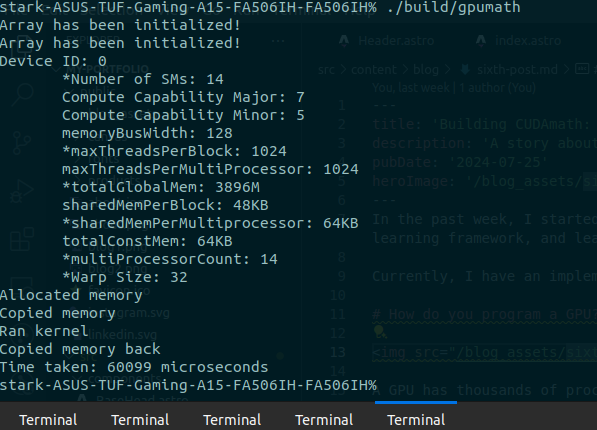
However, how many entries are we going to compute within a thread? This number greatly depends on your GPU. So how do we get info about our GPU?
void CudaDeviceInfo() {
int deviceId;
cudaGetDevice(&deviceId);
cudaDeviceProp props;
cudaGetDeviceProperties(&props, deviceId);
printf("Device ID: %d\n\
*Number of SMs: %d\n\
Compute Capability Major: %d\n\
Compute Capability Minor: %d\n\
memoryBusWidth: %d\n\
*maxThreadsPerBlock: %d\n\
maxThreadsPerMultiProcessor: %d\n\
*totalGlobalMem: %zuM\n\
sharedMemPerBlock: %zuKB\n\
*sharedMemPerMultiprocessor: %zuKB\n\
totalConstMem: %zuKB\n\
*multiProcessorCount: %d\n\
*Warp Size: %d\n",
deviceId,
props.multiProcessorCount,
props.major,
props.minor,
props.memoryBusWidth,
props.maxThreadsPerBlock,
props.maxThreadsPerMultiProcessor,
props.totalGlobalMem / 1024 / 1024,
props.sharedMemPerBlock / 1024,
props.sharedMemPerMultiprocessor / 1024,
props.totalConstMem / 1024,
props.multiProcessorCount,
props.warpSize);
}For my GPU (Nvidia GTX 1650), I found out that each block having 256 threads and each thread computing 4 entries in the output matrix, gives me the best results.
__global__ void sgemm_1d_blocktiling(float *a, float *b, float *c, int m, int n, int common_dim, float alpha, float beta){
const uint BlockSize = 64;
const uint out_COL = blockIdx.x;
const uint out_ROW = blockIdx.y;
const int n_entries = 4;
__shared__ float a_shared[BlockSize * BlockSize];
__shared__ float b_shared[BlockSize * BlockSize];
const uint local_COL = threadIdx.x % BlockSize;
const uint local_ROW = threadIdx.x / BlockSize;
a += out_ROW * BlockSize * common_dim;
b += BlockSize * out_COL;
c += out_ROW * BlockSize * n + BlockSize * out_COL;
// store the results in thread-local memory
float threadResults[n_entries] = {0.0};
for (uint i = 0; i < common_dim; i+=BlockSize){
a_shared[local_ROW * BlockSize + local_COL] = a[local_ROW * common_dim + local_COL];
b_shared[local_ROW * BlockSize + local_COL] = b[local_ROW * n + local_COL];
__syncthreads();
a += BlockSize;
b += BlockSize * n;
for (uint j = 0; j < BlockSize; ++j){
float tmpB = b_shared[j * BlockSize + local_COL];
for (uint k = 0; k < n_entries; ++k){
threadResults[k] += a_shared[(local_ROW * n_entries + k) * BlockSize + j] *tmpB;
}
}
__syncthreads();
}
for (uint k = 0; k < n_entries; ++k){
c[(local_ROW * n_entries + k)*n + local_COL] = alpha * threadResults[k] + beta * c[(local_ROW * n_entries + k) * n + local_COL];
}
}With the above kernel, I was able to compute product of two 256x256 matrices in 0.6 seconds.
For Reference, Look into the following article => https://siboehm.com/articles/22/CUDA-MMM
What next?
We could continue optimizing our sgemm kernel, however, there are a few reasons I plan on putting that for some other day: 1. I need to learn more about Profiling and benchmarking of GPU operations. The time taken for a single execution isn’t exactly a good measure 2. Better to proceed further to building neural networks and come back here, when necessary.
Thus, I plan on stopping here for now, concerning optimizing the sgemm kernel and moving forward with building the components of a neural network.