Dive into Speech Synthesis using Neural Networks
WaveNet
Introduced in 2016 in [@oordWaveNetGenerativeModel2016].
Operates on the raw audio waveform. Modelled as a autoregressive distribution with each audio sample depending on all the previous timesteps. It is modelled using a stack of convolutional layers. A softmax is added at the end to output a probability distribution of the next value. Softmax Distribution is used as a categorical distribution is more flexible. Optimized using the log-likelihood of the next value.
Dilated Causal Convolutions
Uses causal convolution to ensure that each output token just depends on the previous values and not on the future values.
In a 2D case, we might use masking, but in a 1D case, we could just shift the output of the previous layer.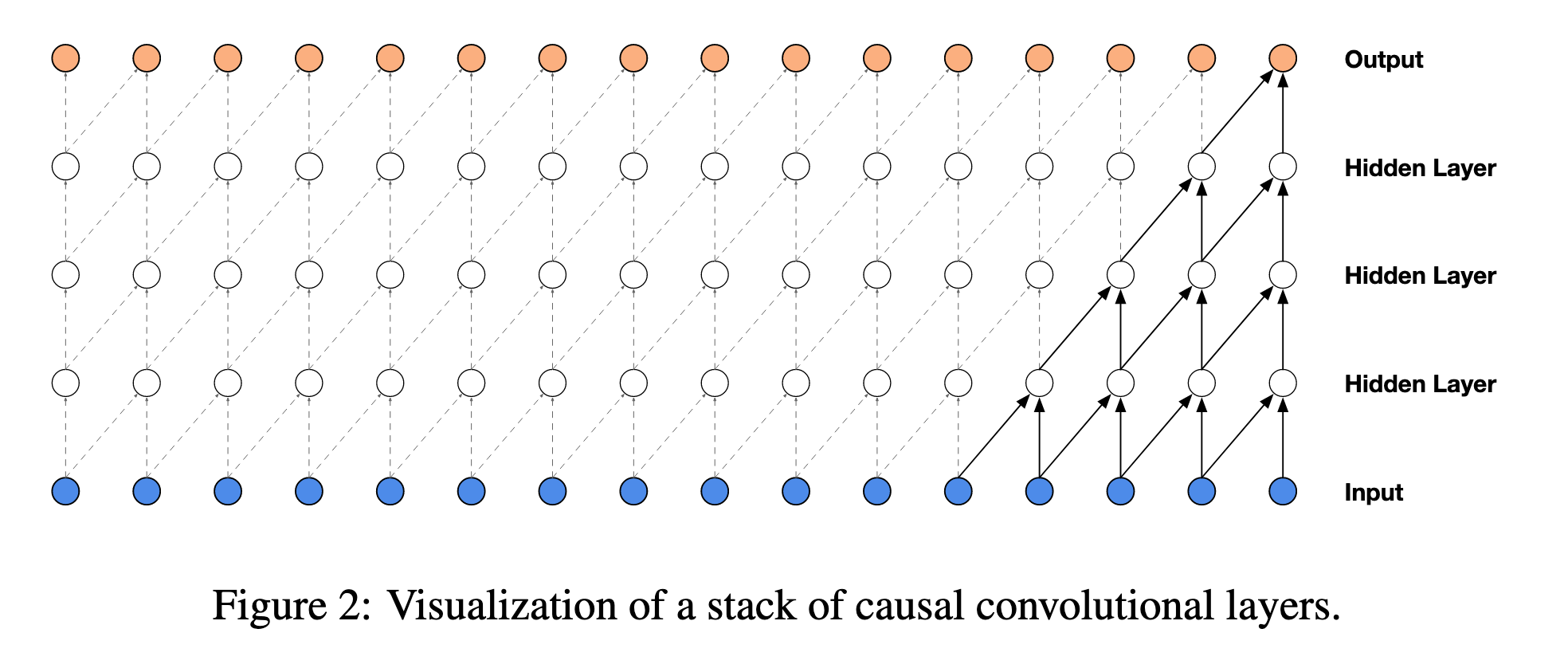
(Image taken from @oordWaveNetGenerativeModel2016)
However, there is an issue here, as the receptive field is dependent on the depth, resulting in a very small receptive field.
Thus, to increase the receptive field, Dilated Convolutions are used.
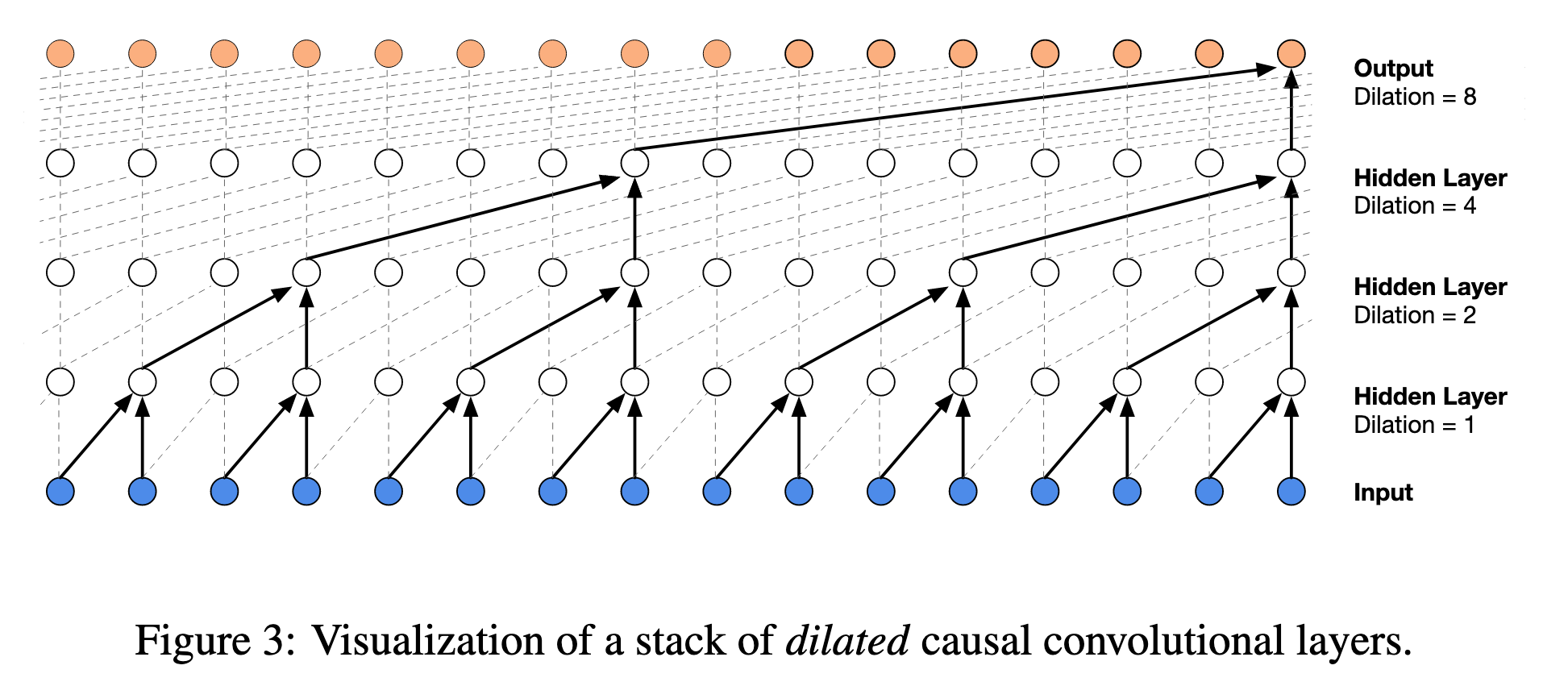
(Image taken from [@oordWaveNetGenerativeModel2016])
Softmax Distribution
Raw Audio - Usually stored as 16-bit integer values per timestep - So we have 65536 possible values.
Too many values, so to make it tractable -
Activation Layer - Gated Activation Units
Two set of weights, one for the filter
Residual and Skip Connection
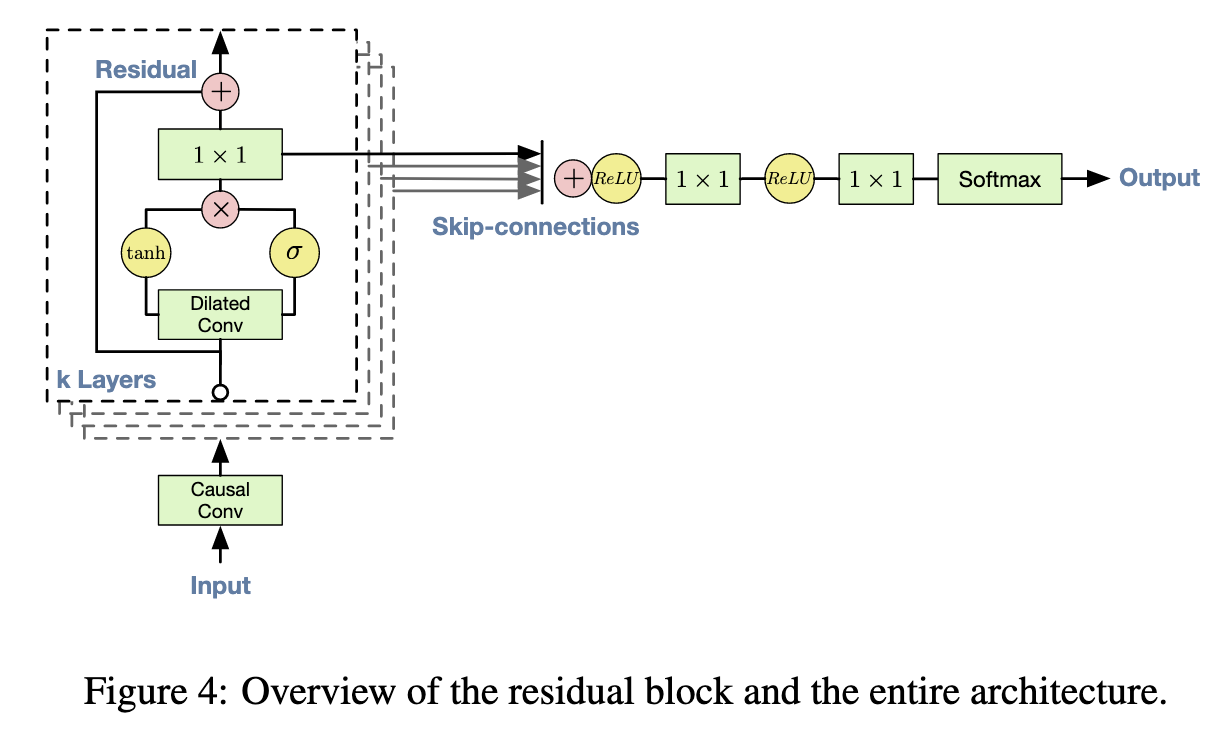
There is a skip connection before the Dilated Convolution.
Conditional Guidance
Two forms of Conditioning
- Global Conditioning - One embedding that influences the output distribution across all timesteps.
- You can add a weighted addition of the embedding in the gated activation unit. $$z = tanh(W_{f,k}*x + V_{f,k}^T h) \odot \sigma(W_{g,k}*x + V_{g,k}^Th)$$
- Local Conditioning - Another Time Series Input.
- Use Transposed Convolution to map to a new time series with the same resolution of the audio signal.$$z = tanh(W_{f,k}*x + V_{f,k}*y) \odot \sigma(W_{g,k}*x + V_{g,k}*y) $$
Tactotron 2
Introduced in 2018 in [@shenNaturalTTSSynthesis2018]
Wavenet takes in a list of amplitudes to generates the wave form. However, it is tough to generate the input to Wavenet. Therefore, we need a way to convert text into magnitude spectrogram. That's where Tactotron 2 comes in, it takes text as input and generates the mel spectrogram.
Similar to a spectrogram, it describes the intensity of frequencies present in a signal. However it is plotted against the mel scale which is more accurate to how humans perceive sound.
Mel-frequency Spectrogram is a non-linear transformation of the linear frequency spectrogram (STFT magnitude).
Model Architecture
Mel Spectrogram are computed through STFT with 50ms frame size, 12.5 ms frame hop and a Hann window function.
Using a 5 ms frame hop increases the temporal resolution given rise to more significant pronunciation issues.
STFT magnitude to the mel scale -> 80 channel mel filterbank spanning 125 Hz to 7.6 kHz.
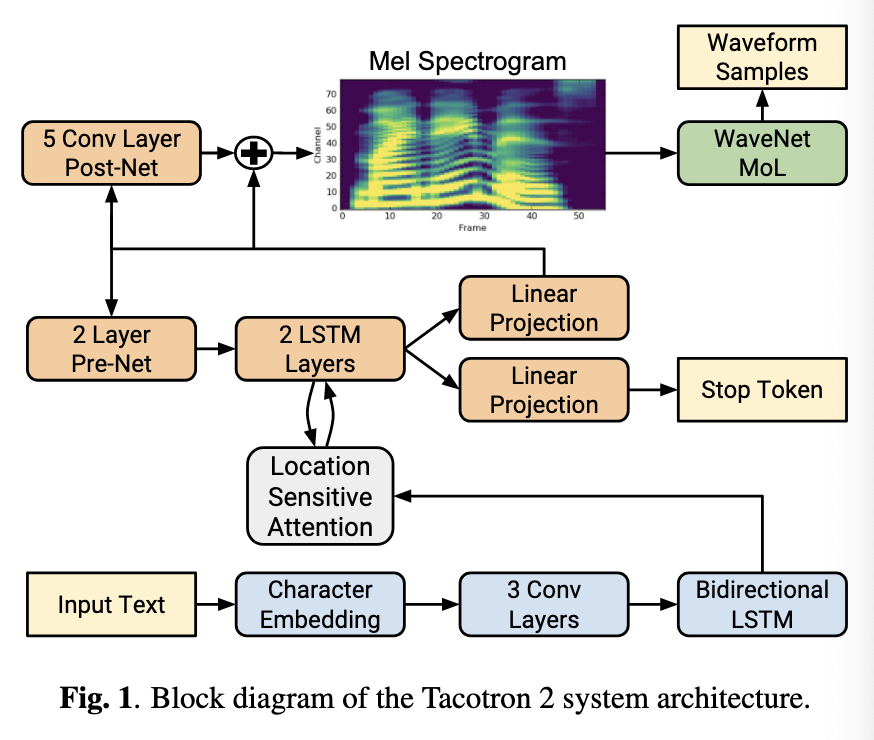
(Image taken from [@shenNaturalTTSSynthesis2018])
Encoder - Character Sequence to a Latent Representation
Decoder - Consumer Latent Representation to produce spectrogram.
Location Sensitive Attention to summarize the encoder output and pass it through each decoder step.
Wavenet Vocoder
Vocoder - Go from mel spectrograms to time-domain waveform samples - Use a WaveNet Architecture instead of using a softmax distributions to put it into bins, and use a 10 component mixture of logistic distributions (MoL) - Use ReLU followed by Linear Layers
FastSpeech and FastSpeech 2
The earlier methods were autoregressive, thus really slow but then [@renFastSpeechFastRobust2019] introduced a Transformer-based method to generate the mel-spectrogram in parallel for TTS.
Aside from the fact that it gives rise to slow inference,
- Propagates error overtime
- It was hard to control as the voice was generated automatically from mel spectrograms.
FastSpeech
Architecture
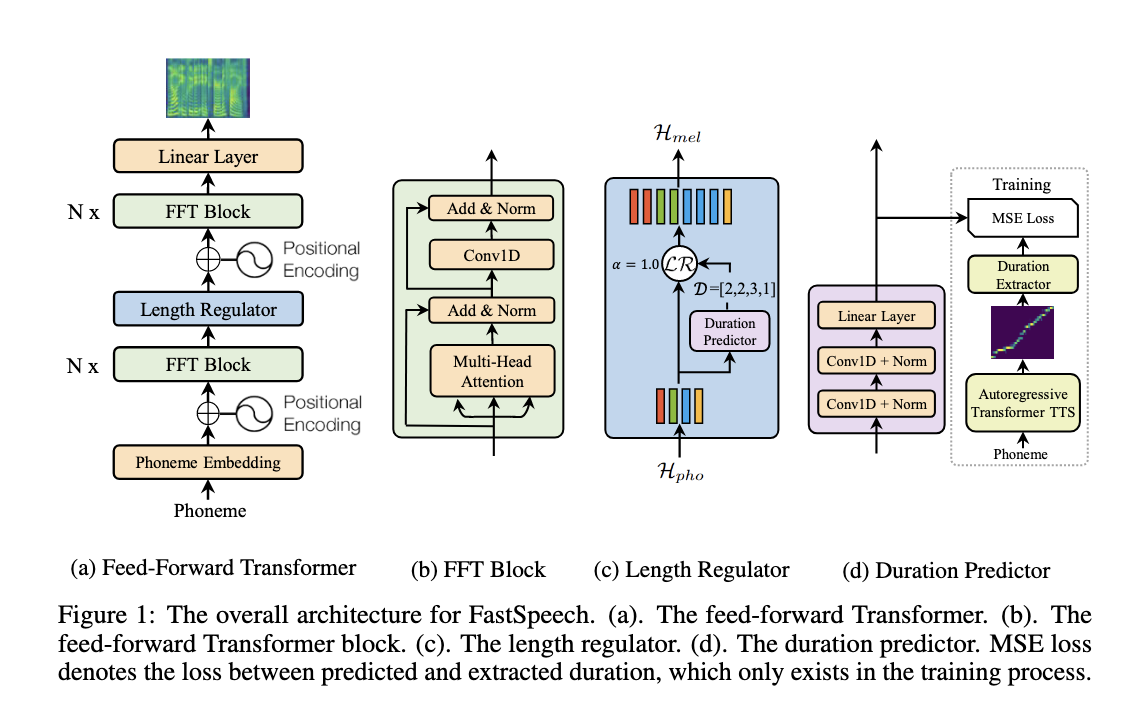
Core Architecture - Attention + Residual Connections + LayerNorm + 1D Convolution
Length Regulator
Solves the problem of length mismatch between the phoneme and spectrogram sequence in the Feed Forward Transformer.
Each phoneme could correspond to several mel-spectrograms. Length of mel-spectrograms that correspond to phoeneme is called the phoneme duration.
Given
The output of Length regulator is given by $$ H_{mel} = LR(H_{pho},D,\alpha)$$
Multiply
Length Regulator basically just repeats the Hidden states as many times as dictated by the number mentioned
To predict the duration, a separate predictor network is used consisting 2 layers of 1D Convand ReLU. This module is jointly trained with the core architecture by stacking this on top of FFT blocks. We just compare against the output duration of an autoregressive TTS model. However this is a complex process to do so and it was removed in Fast Speech 2
FastSpeech 2
Issues with FastSpeech
- Teacher-Student Distillation Pipeline is complicated and time-consuming, when training the Duration Predictor
- Duration extracted is not accurate enough and the target extracted from the teacher is not good enough in terms of voice quality.
(TO BE CONTINUED)
References
[1]
A. van den Oord et al., “WaveNet: A Generative Model for Raw Audio,” Sep. 19, 2016, arXiv: arXiv:1609.03499. doi: 10.48550/arXiv.1609.03499.
[2]
J. Shen et al., “Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions,” Feb. 16, 2018, arXiv: arXiv:1712.05884. doi: 10.48550/arXiv.1712.05884.
[3]
Y. Ren et al., “FastSpeech: Fast, Robust and Controllable Text to Speech,” Nov. 20, 2019, arXiv: arXiv:1905.09263. doi: 10.48550/arXiv.1905.09263.