Embeddings after 2020
I have covered the basics of Word Embeddings in Word Embeddings to Sentence Embeddings, but what are some new ideas in the general field of embeddings in the last 5 years?
Matryoshka Representation Learning (2022)
Question: Can we have a representation that can adapt to multiple downstream tasks with varying levels of computational resources?
Introduced in [@kusupatiMatryoshkaRepresentationLearning2024], Matryoshka Representation Learning encodes information at different scales. Matryoshka dolls are russian dolls which nest within each other.

When training, the authors explicitly optimize lower dimensional vectors within the same high dimensional vectors, thus you get the name Matryoshka.
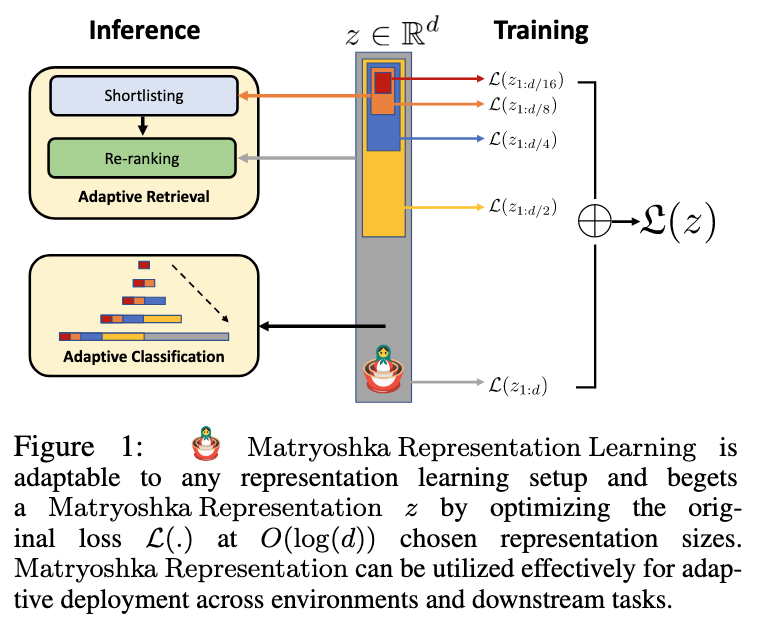
(Image taken from [@kusupatiMatryoshkaRepresentationLearning2024])
This cascaded representation could be used in applications like Classfication and Retrieval. For example, in Retrieval, we could first retrieve with the smallest embedding and then increase in size till we get our desired set of results.
The training objective is as follows
- Calculate the softmax cross entropy loss for a linear classifier based on the given embedding size
- Do a weighted sum of that for all the linear classifiers with each of them having a different embedding size.
- Average the loss across the whole dataset.
That is the loss, the authors are trying to minimize.
The authors have found that it is best to give a uniform importance scale. They also found that the representations actually interpolate across sizes, despite training for fixed embedding sizes.
References
[1]
A. Kusupati et al., “Matryoshka Representation Learning,” Feb. 08, 2024, arXiv: arXiv:2205.13147. doi: 10.48550/arXiv.2205.13147.