Mixture of Experts (MoE)
The scale of model => One of the most important axes for better model quality.
Given a fixed computing budget, training a larger model for fewer steps is better than training a smaller model for more steps.
MoE => allows model to be pre-trained with far less compute and achieves good quality faster.
In the context of transformer models, MoE consists of two main elements
- Sparse MoE layers => Used instead of dense feed-forward FFN layers. It has a certain number of experts, where each expert is a neural network (Usually experts are FFNs, but they could be anything.)
- A gate network or router => Determines which tokens are sent to which expert. The router is composed of learned parameters and is pre-trained at the same time as the rest of the network
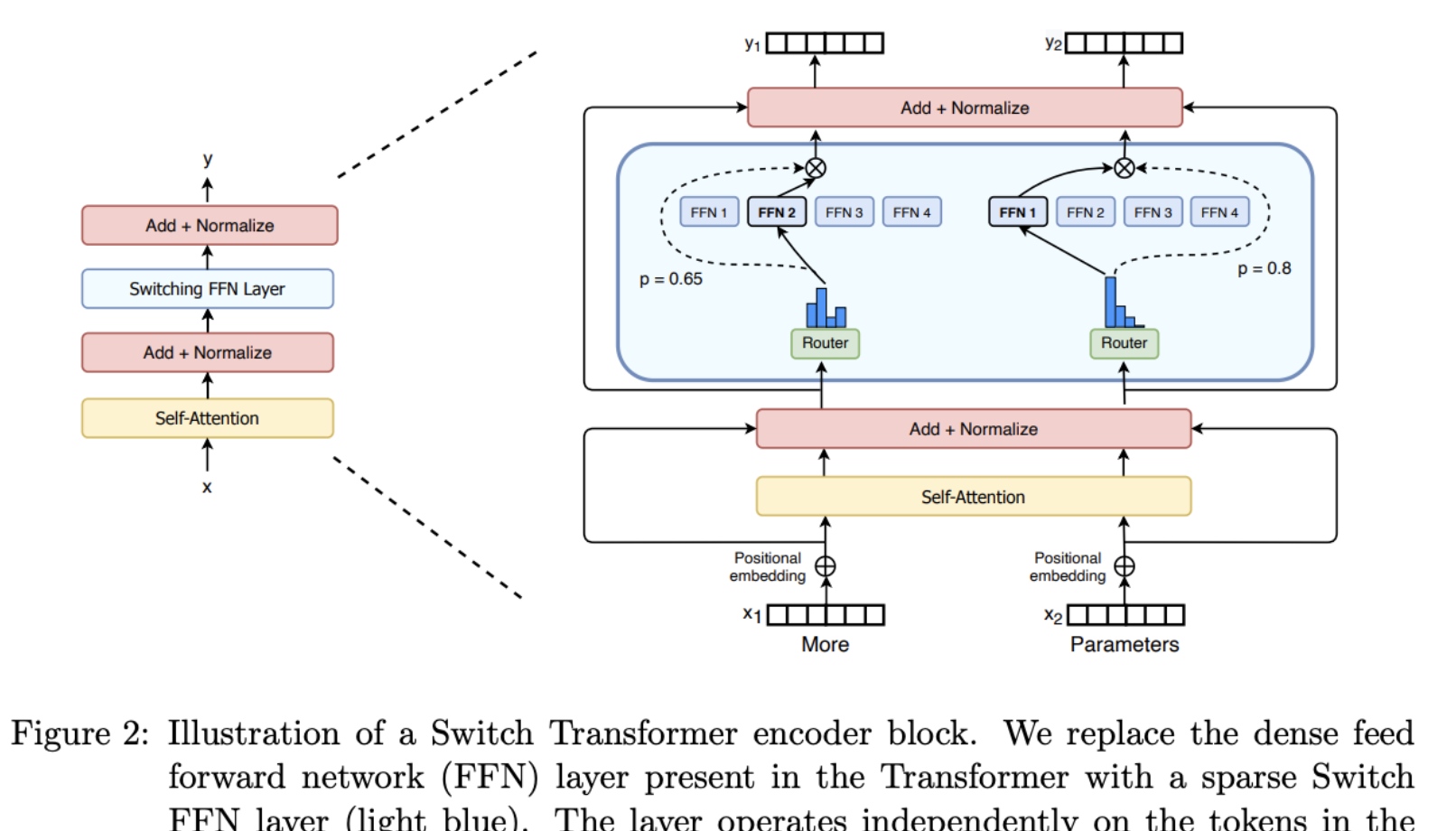
Illustration of MoE block in Switch Transformer paper
Challenges -
- Historically struggled to generalize during fine-tuning, leading to overfitting.
- Even though a MoE has a lot of params, only some of them are used during inference, leading to good speeds, but still we have to load all the params in memory.
For example, given a MoE like Mixtral 8x7B, we’ll need to have enough VRAM to hold a dense 47B parameter model. Why 47B parameters and not 8 x 7B = 56B? That’s because in MoE models, only the FFN layers are treated as individual experts, and the rest of the model parameters are shared. At the same time, assuming just two experts are being used per token, the inference speed (FLOPs) is like using a 12B model (as opposed to a 14B model), because it computes 2x7B matrix multiplications, but with some layers shared (more on this soon).
History of MoEs
Roots - 1991, Adaptive Mixture of Local Experts
Between 2010-2015,
- Experts as components - In the traditional MoE setup - the whole system comprises a gating network and multiple experts. While https://arxiv.org/abs/1312.4314 - introduced the idea of it being components in deep models
- Conditional Computation
Sparsity
Idea of Conditional Computation. However this introduces some challenges, although large batch sizes are usually better for performance, batch sizes in MOEs are effectively reduced as data flows through the active experts. It could lead to uneven batch sizes and underutilization.
A simple Linear Layer with Softmax activation is used as the gating network
How to load balance tokens for MoEs? If all our tokens are sent to just a few popular experts, it makes training inefficient. In a normal MoE training, the gating network converges to mostly activate the same few experts. This self-reinforces as favored experts are trained quicker and hence selected more. To mitigate this, an auxillary loss is added to encourage giving all experts equal importance. There is also the concept of expert capacity => Introduces a threshold of how many tokens can be processed by an expert.
MoEs and Transformers
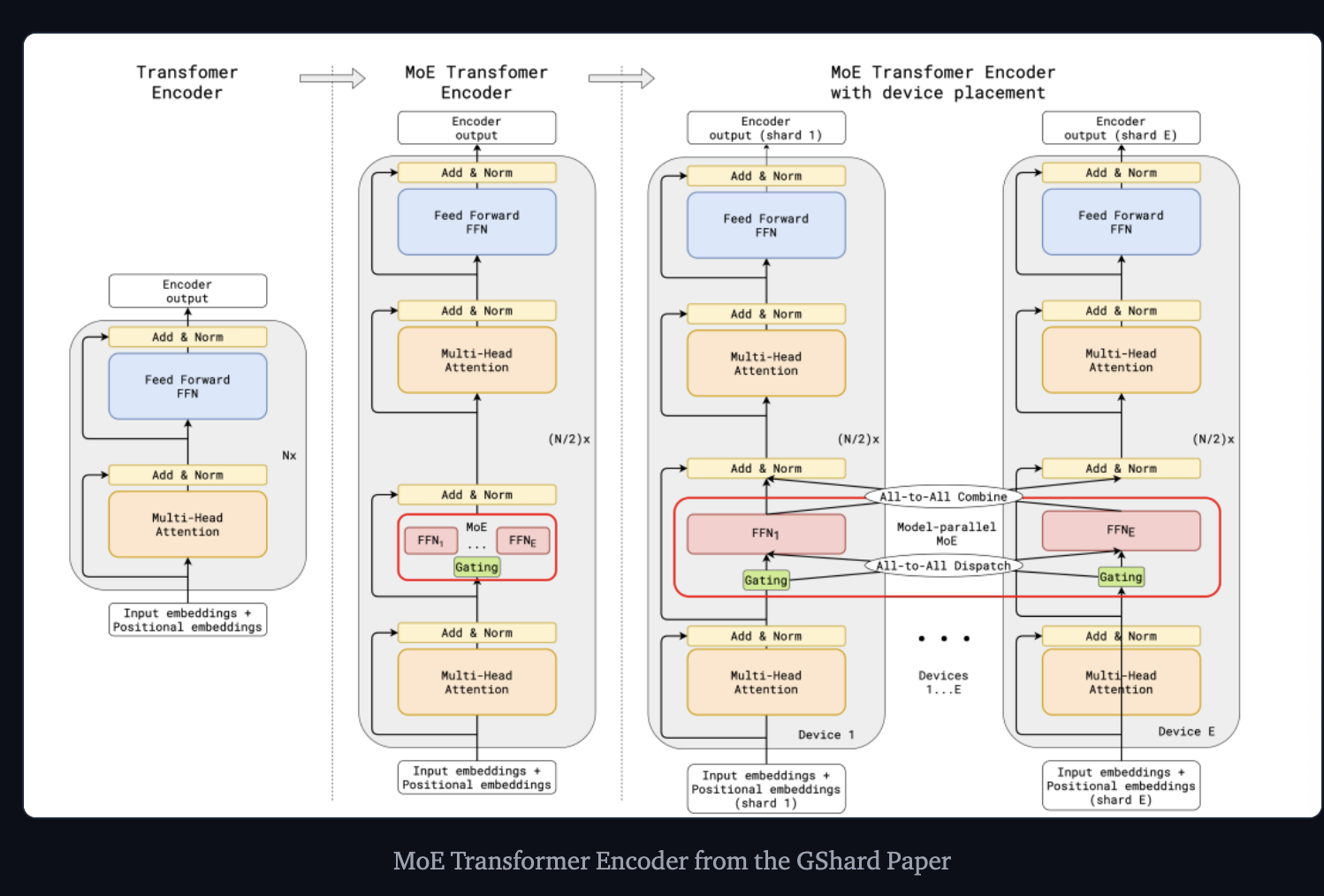
Google GShard - which explores scaling up transformers beyond 600 billion parameters. - Replaces every other FFN layer with an MoE layer using top-2 gating in both the encoder and the decoder.
When scaled to multiple devices, the MoE layer can be just shared across devices while all the other layer can be replicated.
In a top-2 setup, we always pick top expert, but the second expert is picked with a probability proportional to its weight.
Expert capacity - Set a threshold of how many tokens can be processed by one expert. If both experts are at capacity, the token is consdiered overflowed, and its sent to the next layer via residual connections.
GShard Paper => Also talks about parallel computation patterns that work well for MoEs
Switch Transformer Paper => The authors replaced the FFN layers with a MoE layer => Receives two inputs (two different tokens) and has four experts.
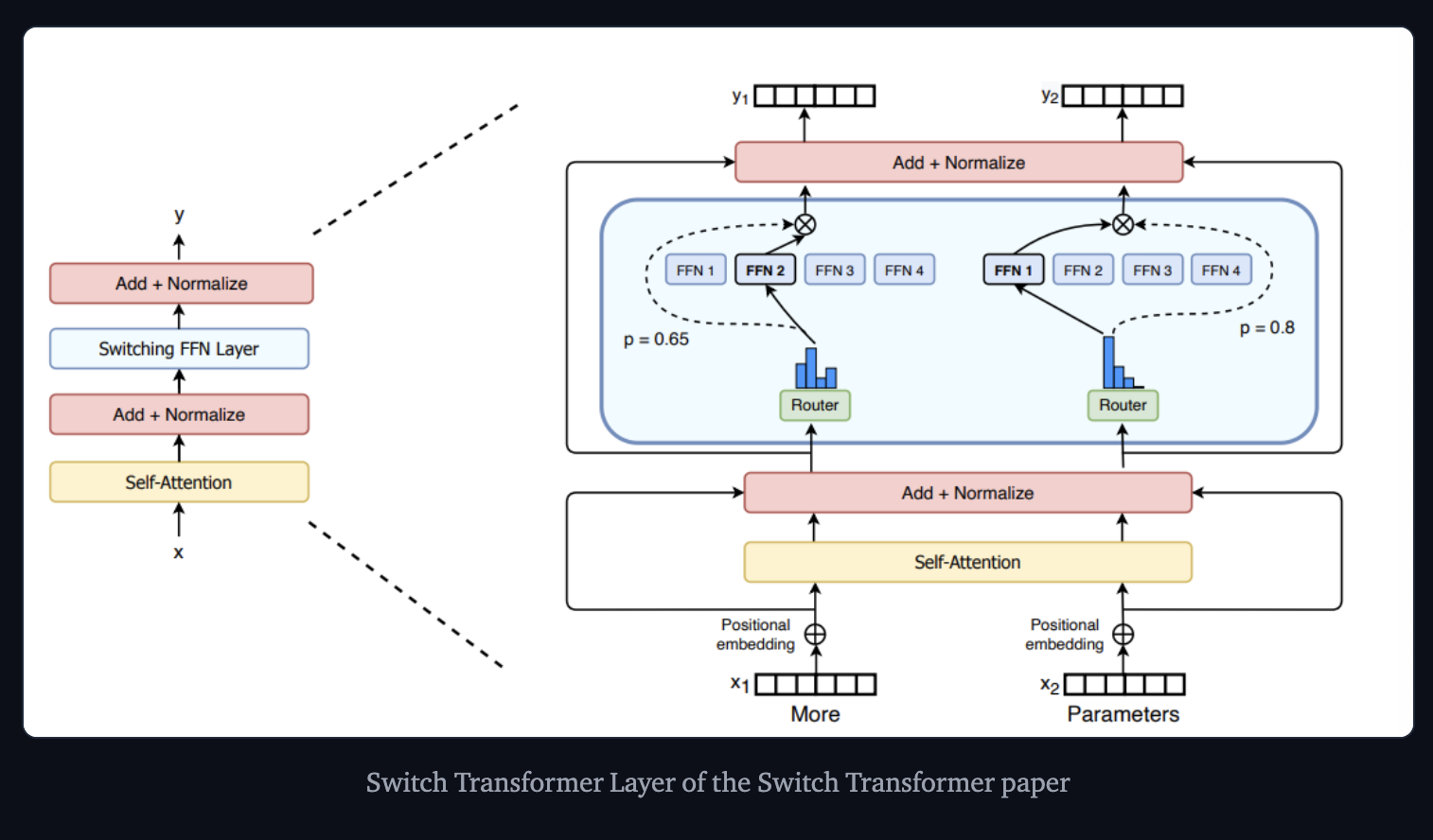
Switch Transformer uses just a simplified single-expert strategy, causing the following
- The router computation is reduced
- The batch size of each expert can be at least halved
- Communication costs are reduced
- Quality is preserved.
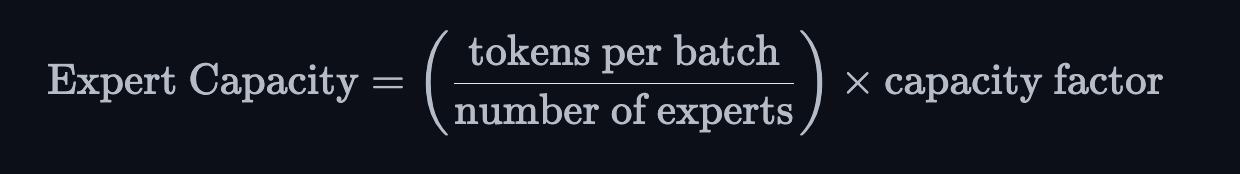
If we use a capacity factor greater than 1, we provide a buffer for when tokens are not perfectly balanced, However increasing the capacity will lead to more expensive inter-device communication, so it's a trade-off to keep in mind.
For each Switch Layer, the auxillary loss is added to the total model loss during training. The authors also used selective precision (i.e use bfloat16 for MoE layers and float32 for other layers).
However, the load balancing auxillary loss could lead to instability issues. At the expense of quality, we can stabilize training, by introducing dropout.
In ST-MoE, Router z-loss is introduced which significantly improves training stability without quality degradation by penalizing large logits entering the gating network.
What does an expert learn?
Encoder experts specialize in a group of tokens or shallow concepts (i.e proper noun expert, punctuation expert and so on). On the other hand, the decoder experts have less specialization.
The authors of St-MOE also noticed that when trained in a ultilingual setting, instead of specializing in a language, there is noting like that
Scaling w.r.t number of experts
More experts lead to improved sample efficiency and faster speedup but these are diminishing gains (especially after 256 or 512).
Fine-tuning MoEs
Sparse models are more prone to overfitting - so we can explore higher regularization within the experts themselves.
Whether to use the auxillary loss for fine-tuning? The ST-MoE authors experimented with turning off the auxiliary loss, and the quality was not significantly impacted, even when up to 11% of the tokens were dropped. Token dropping might be a form of regularization that helps prevent overfitting.
The authors of Switch Transformers observed that at a fixed pretrain perplexity, the spare model does worse than the dense counterpart in downstream tasks, especially on reasoning heavy tasks. However on knowledge heavy tasks it performs disproportionately well. 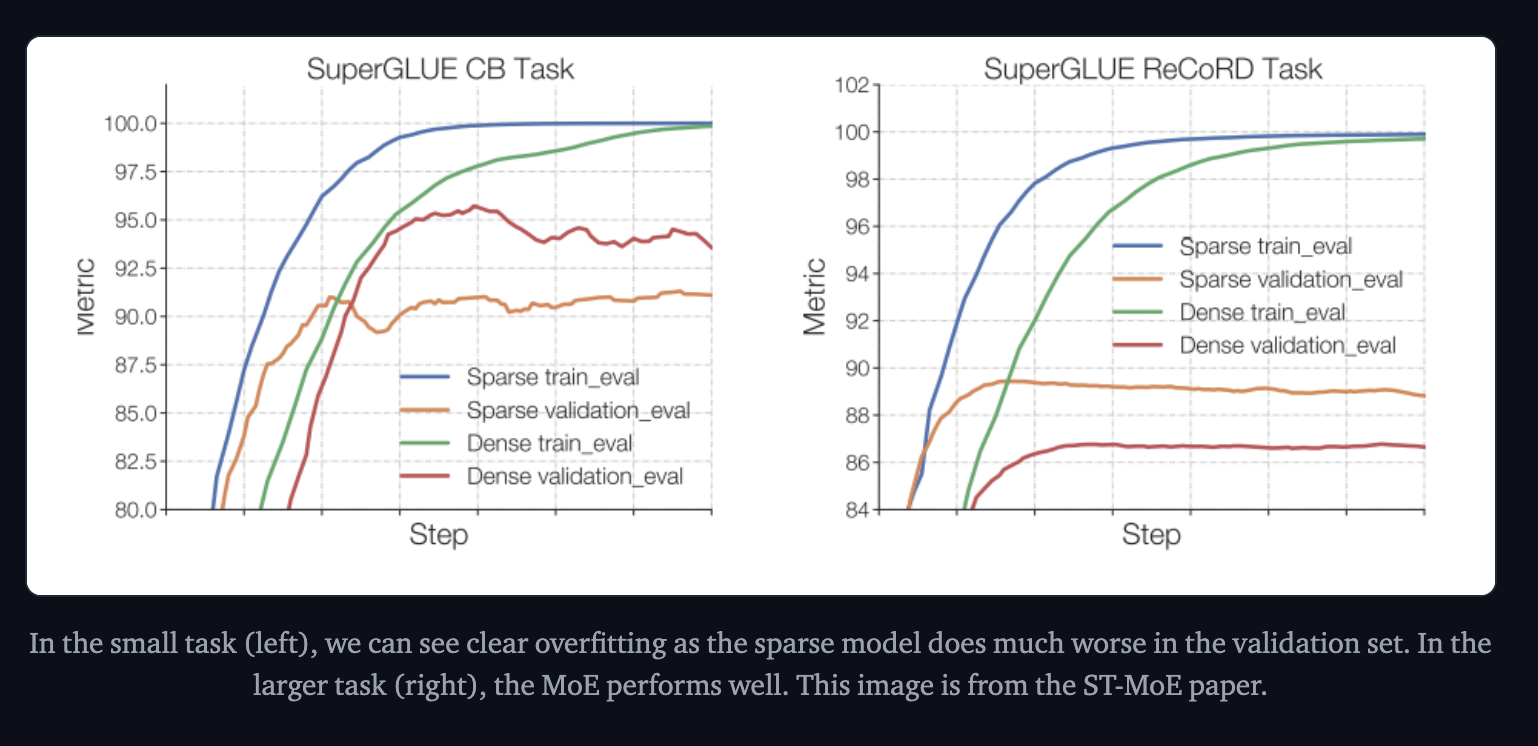
Freezing all non-expert weights and then finetuning leads to huge performance drop. However, the opposite, freezing only the MoE params worked almost as well as updating all parameters.
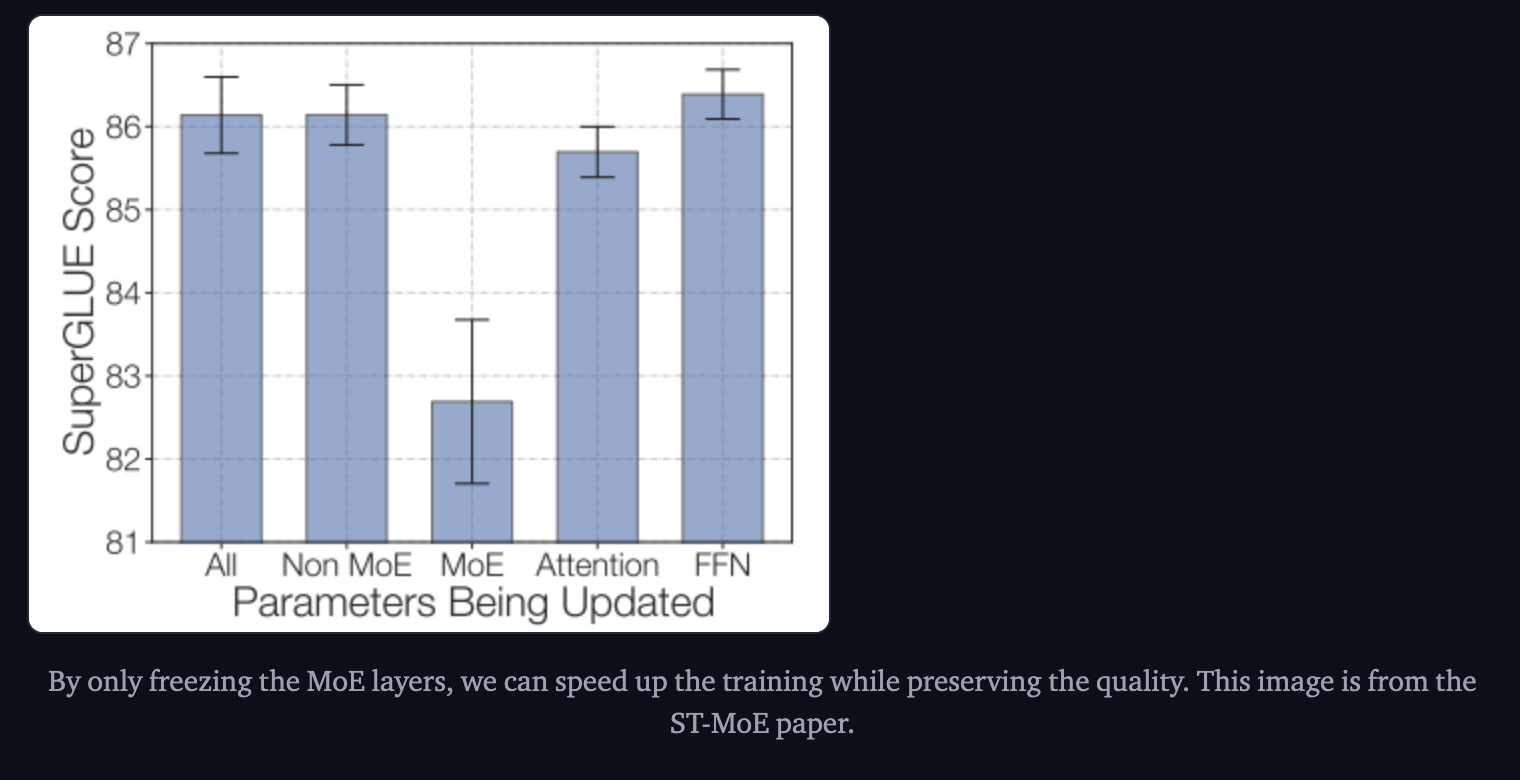
Sparse models tend to benefit more from smaller batch sizes and higher learning rates.
MoEs Meets Instruction Tuning(July 2023), performs experiments doing
- Single Task Fine Tuning
- Multi Task Instruction Tuning
- Multi Task Instruction Tuning followed by Single task fine-tuning
They indicate the MoEs might benefit much more from instruction tuning. The auxillary loss is left on here, and it prevents overfitting
Experts are useful for high throughput scenarios with many machines
Making MoEs go brr
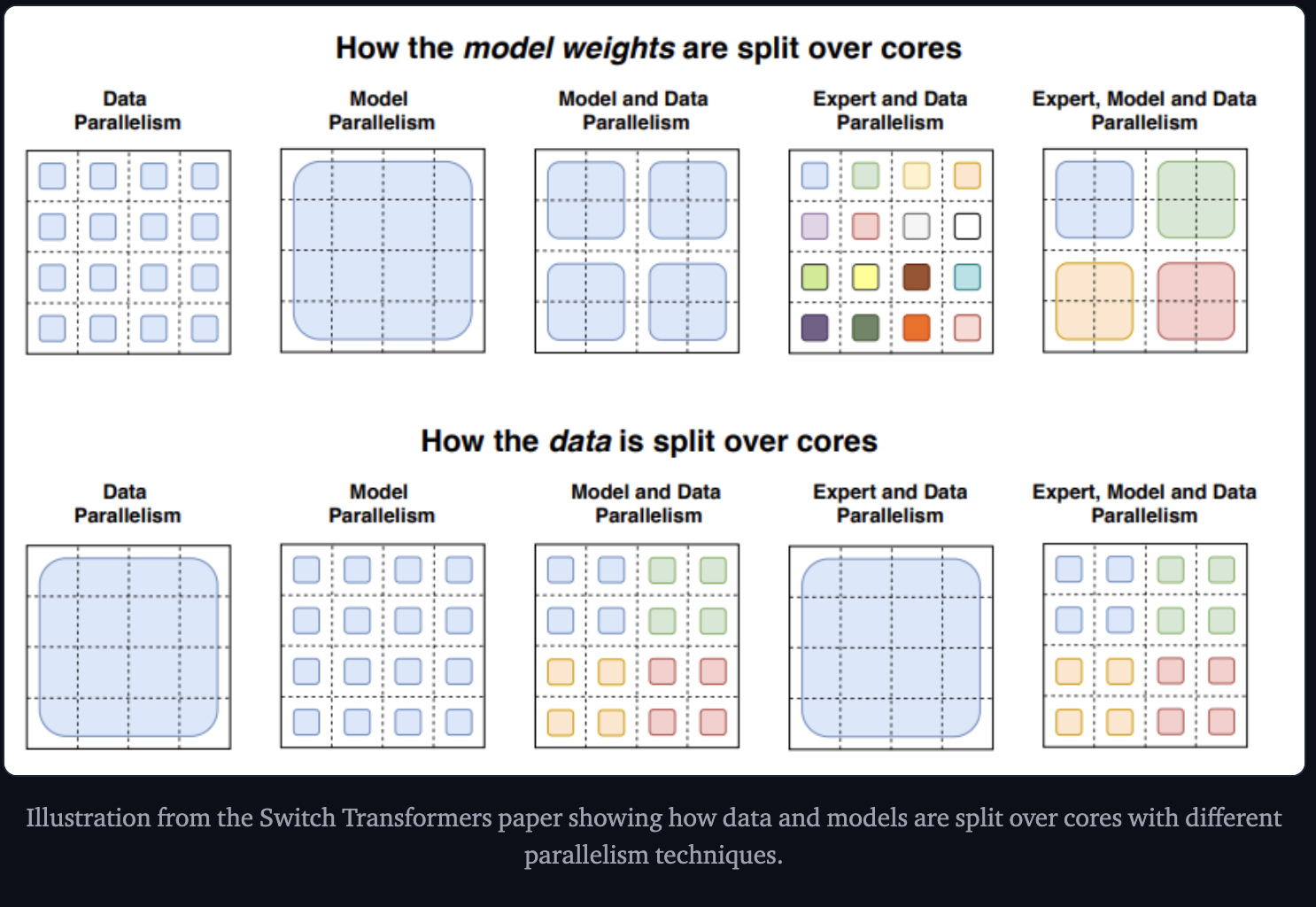
Parallelism
- Data Parallelism - the same weights are replicated across all the cores and the data is partitioned across cores
- Model Parallelism - The model is partitioned across cores, and the data is replicated across cores
- Model and Data Parallelism - partion both across cores. Different cores process different batches of data.
- Expert Parallelism - Experts are placed on different workers and each workes takes a different batch of training samples.
Capacity Factor
Increasing the capacity factor increases the quality but increases communication costs and memory of activations. A good starting point is using top-2 routing with 1.25 capacity factor and having one expert per core.
Serving Techniques
The Switch Transformers authors did early distillation experiments. By distilling a MoE back to its dense counterpart, they could keep 30-40% of the sparsity gains. Distillation hence provides the benefits of faster pretraining and using a smaller model in production.
There are approaches to modify the routing to route full sentences or tasks to an expert, permitting extracting sub networks for serving
Aggregation of Experts - Merges the weights of the experts, hence reducing the number of parameters at inference time.
Efficient Training
FasterMoE and Megablocks.