Post Training Alignment Techniques
Given a parrot which could say your next word, how to make it a useful assistant? Alignment Techniques!!
Instruction Fine Tuning
Allows the model to follow instructions.
[1] showed that fine-tuning language models on a collection of datasets described via instructions improves the model's performance to follow arbitrary unseen instructions. This process of finetuning is called as Instruction-tuning
The authors combined existing NLP datasets and made templates which would use natural language instructions to describe the task for that dataset.
For classification tasks, a special token OPTIONS is used and all the available options are given afterwards. This allows the model to learn about the existing options and makes the model to focus on particular outputs.
The authors also discovered that instruction tuning hurts small models by reducing their generalization capabilities as they may not have enough model capacity. However, it helps large models greatly.
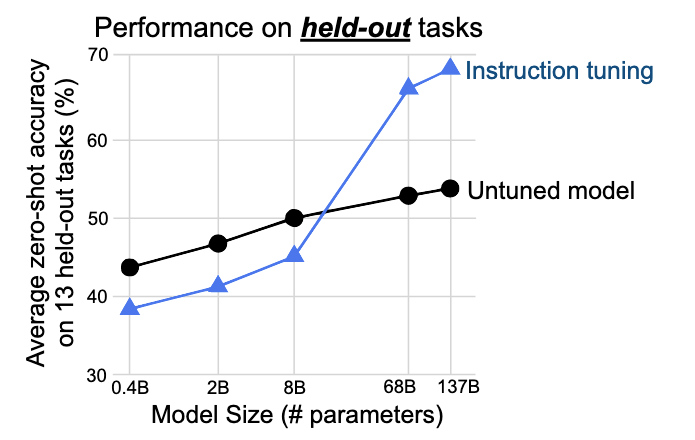
(Image taken from [1])
Reinforcement Learning through Human Feedback - InstructGPT
To better align with humans, it is better if we could use human feedback directly. That's the problem RLHF tries to solve.
Introduced in [2]
Core Idea - Given a dataset of comparisons of Outputs from models and which humans prefer, train a Reward Model to predict which outputs users would prefer. Use a Reinforcement Learning Algorithm(PPO) with the reward from Reward Model. How do you go from which outputs users would prefer to a reward??
The Bradley Terry Model
Given
- the question - the winning answer (the ones user preferred) - the ones which the users didn't like
The above model models the probability of
When we write in terms of softmax and modelling the log probability, we get the following loss objective:
Implementation Details
Before training the reward model, the language model undergoes supervised fine-tuning/instruction-tuning on a dataset of instructions and desired responses.
Implementation Details:
All models use fp16 weights and activations, with fp32 master copis of weights. Byte-pair encoding is used for all models. Trained with Adam Optimizer with beta_1 = 0.9 and beta_2 = 0.95.
RL policy context length - 2k tokens
SFT (Supervised Fine-tuning)
- Cosine Learning Rate Decay
- Residual Dropout of 0.2
- Trained for 16 epochs
It is common to see overfitting in validation loss after 1 epoch, but it helps with reward modelling despite the overfitting.
Reward Modelling
Replace the unembedding layer with a projection layer to output scalar values
Used a 6B GPT-3 Model as base and trained for 1 epoch
After training reward model, we could apply PPO in an environment with the the customer prompt as input and the output from the model is given to the reward model to predict the reward. (Note: I am working on an article about different policy optimization algorithms, I will cover PPO in depth in that article.)
The RLHF Objective
While we want the model to try for high reward, we shouldn't want the model to output utter gibberish. For instance, the model could identify that using Please or Kindly gives good rewards, and then just output "Please Kindly Please Kindly ....". Thus, we don't the model to diverge a lot from the earlier outputs of language model.
Therefore the authors added a per-token KL Divergence penalty term to the objective function.
The second term within the first expectation is the KL penalty.
The authors noticed that after pre-training with just the first two terms, there was a dip in performance in standard NLP tasks.
Thus to avoid that dip in performance, they make sure to sample the input from pre-training datasets and maximize the log probability as well. This is termed as the pre-training mix.
Direct Preference Optimization
RLHF helps the model to align with the user's intent, however the process is quite complex and has too many components. That's the problem Direct preference Optimization is trying to solve.
Introduced in [3], DPO tries to solve this problem without the use of Reinforcement Learning.
Instead of trying to fit a reward model and then optimize a policy based on the reward from the reward model, the authors found a way to loss functions over reward into loss function over policies.
The authors found an optimal solution to the RLHF objective. (The Pre-training term is ignored.)
The optimal solution policy to the maximize the RLHF objective is given as
where $$ Z(x) = \Sigma_y\pi_{ref}(y|x) exp(\frac{1}{\beta}r(x,y))$$
The
After taking the logarithm and some algebra, we can write the reward model as
To maximize the probability distribution of preference of
As you can see, only the difference terms matters, so
Thus substituting we get the loss objective for DPO
Given a dataset of sample completions and human preferences over it, we could train the model based on this objective directly, without the use of Reinforcement Learning.
The authors also discuss about a few theoretical analysis such as how a language model is also a reward model. However, I need to dive deep into Bradley Terry preference framework before I could read the proofs.
To be Continued
Stuff to be added:
- DPO Proof of Optimal Solution
- GRPO
References
[1]
J. Wei et al., “Finetuned Language Models Are Zero-Shot Learners,” Feb. 08, 2022, arXiv: arXiv:2109.01652. doi: 10.48550/arXiv.2109.01652.
[2]
L. Ouyang et al., “Training language models to follow instructions with human feedback,” Mar. 04, 2022, arXiv: arXiv:2203.02155. doi: 10.48550/arXiv.2203.02155.
[3]
R. Rafailov, A. Sharma, E. Mitchell, S. Ermon, C. D. Manning, and C. Finn, “Direct Preference Optimization: Your Language Model is Secretly a Reward Model,” Jul. 29, 2024, arXiv: arXiv:2305.18290. doi: 10.48550/arXiv.2305.18290.