Retrieval Augmented Generation
Using a Non-parametric memory (basically a vector database) to store relevant data and then using a trained neural retriever to retrieve relevant data. This makes sure that the model uses relevant information than relying on the pre-trained weights.
It was introduced in [1]
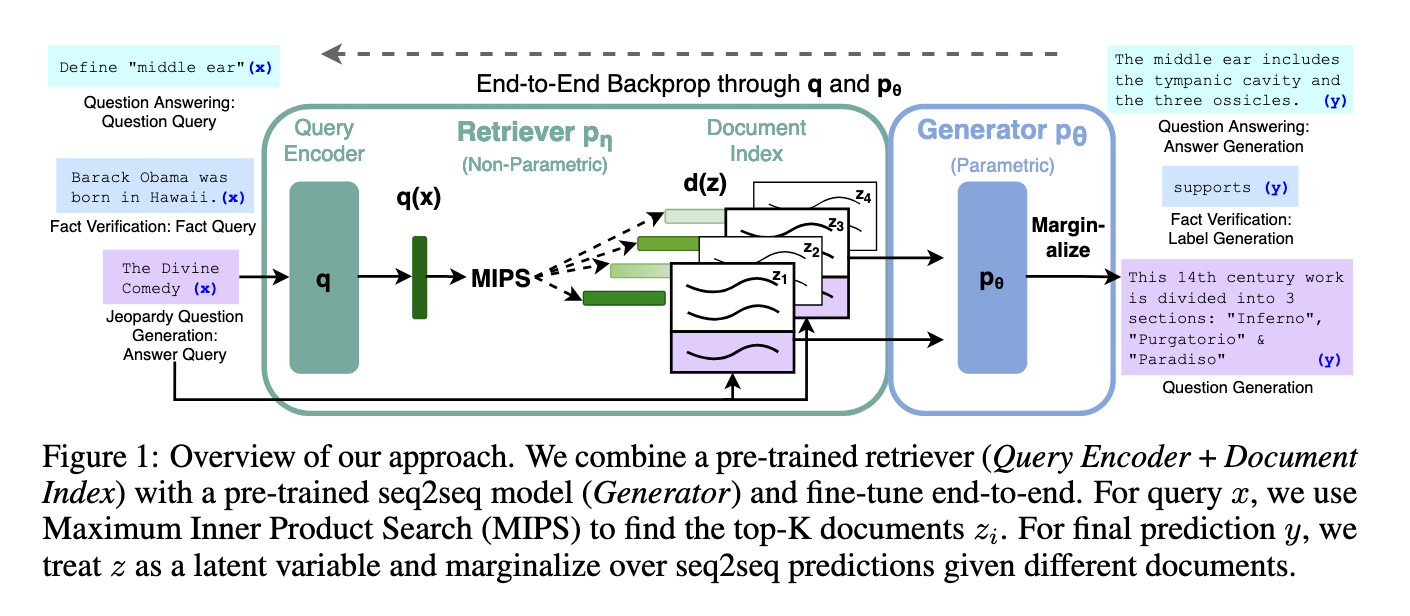
(Image taken from [1] )
Three Components:
- Neural Retreiver (Ex: Dense Passage Retriever)
- Generative Model (Ex: Transformer)
- Non parametric memory(Ex: Vector Database)
Combine them together and then finetune them.
Treating the retrieved document as a given latent variable to condition the generation. We can either condition on the same document for every target token in a sequence or have a different one for each target token
Dense Passage Retriever - Encode the document and query using BERT and then maximize the inner product of them, this can be done in an approximate manner in sub-linear time. (How it is achieved is an interesting area to look into - I will write about it later)
Only the query encoder and the generator are finetuned.
Self-RAG
The earlier told approach always retrieves documents, irrespective of whether retrieval is necessary. [2] approaches this problem by introducing special tokens, that could enable the model to output special tokens which could indicate generation and reflection on retrieved passages and it's own generations.
The Reflection tokens are as follows
- Retrieval:
- Retrieve - Given the prompt and preceding generation - Decides whether to retrieve
- Critique:
- IsREL - Given the input and document, whether the document is relevant or irrelevant
- IsSUP - Given the input, document and output, whether all of the verification worthy statements are fully supported or partially supported or no support from the document
- isUSE - Given the input and output, give a number from 5 to 1 to rate the output's usefulness to x.
Inference
Given a prompt
- Predict the Retrieve token given the prompt and previous generations
- If the Retrieve Token is true then
- Retrieve passages and generate isReL for each document
- Generate output based on each document and predict isSUP and isUSE
- Rank them based on these three tokens - Basically a linear weighted sum of the normalized probability for each token
- Choose the best one
- If it is False then
- Predict the output
- Predict the isUse token
Training Process - Reflection tokens are added offline by another model such as ChatGPT. As it could be expensive to use ChatGPT, the authors trained their own critic using a dataset created by ChatGPT. The Generator Model is trained using next token objective and it is tasked with predicting the reflection tokens as well.
References
[1]
P. Lewis et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”.
[2]
A. Asai, Z. Wu, Y. Wang, A. Sil, and H. Hajishirzi, “Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection,” Oct. 17, 2023, arXiv: arXiv:2310.11511. doi: 10.48550/arXiv.2310.11511.