RNNs to GPT and BERT
RNNs operates over a Sequences of Vectors
RNN
A one neuron RNN
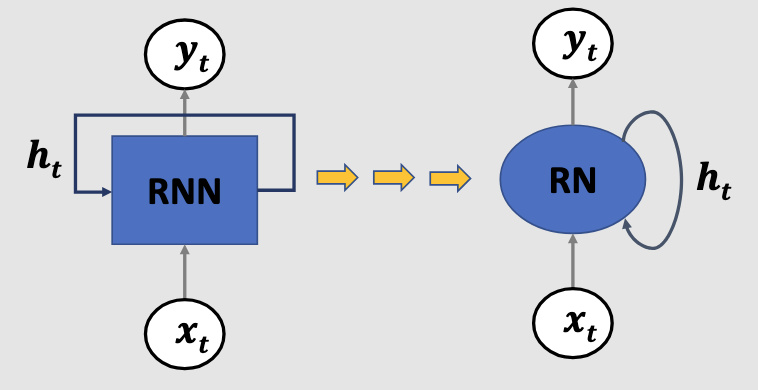
where,
The intuition behind RNNs, is that they could learn to use the past information. However, they can't learn long term dependencies, even though in theory they should be able to do so.
LSTMs are a variant of RNNs made specifically to solve long term dependency problem.
LSTMs
The core idea: We have state information which is passed through all the layers. We regulate adding and removing information from the state through gates.
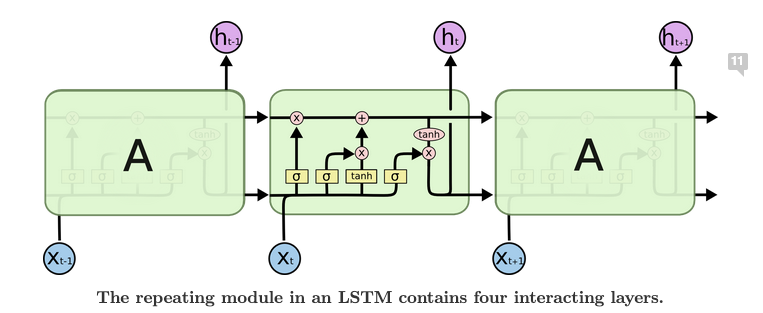
(Image taken from an amazing blog post - https://colah.github.io/posts/2015-08-Understanding-LSTMs/)
There are three gates
- Forget gate - Decides what information is thrown away from the cell state. It is the first
from the left. - The output from the sigmoid is multiplied with the cell state, so that for each value in Cell state is multiplied with a number between 0 to 1 based on the previous hidden state and input.
- Input gate - What information to store in the cell state. it is the second
and the layer in the image$$ i_t = \sigma(W_i[h_{t-1},x_t] + b_i)$$$$C't = tanh(W_c[h,x_t] + b_C)$$$$ a_t = i_t.C'_t$$ - We first calculate the information using the second equation and it is regualted by multiplying with the sigmoid and it then it is added to the cell state.
- Output gate - The Output will be based on the cell state. Thus we use a tanh layer and then use a sigmoid layer to regulate it.
Seq2Seq Models
Both the input and outputs are sequences, and one core downstream application is neural machine translation.
Model = Encoder + Decoder
Encoder -> processes each item in input sequence.
Decoder -> Produces output sequence item by item
The common architecture used for both encoders and decoders used to be some form of RNN (mostly LSTM). The final hidden state from the encoder's LSTM is passed as input to the decoder's input.
However, in this case all of the information from the input sentence is contained in a single vector. This single vector seemed to contain all the relationships of the words in the input sentence so that the decoder can use it to translate.
[@bahdanauNeuralMachineTranslation2016b] Identified the bottleneck and introduced the concept of allowing the encoder to produce context for each word and all the contexts are given to the decoder. The individual contexts from the encoder are multiplied with a score which says how they relate to the current output word. This allows the decoder to focus on relevant parts
While this discovery caused most sequence to sequence tasks to be dominated by models with RNNs and Attention, then came the famous paper, "Attention is all you need"[@vaswaniAttentionAllYou2023] which shows that attention is all you need and you don't need of Recurrent Networks.
Transformers
Traditionally for seq2seq tasks, we use RNNs, LSTMs, Gated Units
Model Architecture
The encoder maps an input sequence of symbol representations to a sequence of continuous representations. Given these, the decoder then generates an output sequence of symbols one element at a time.
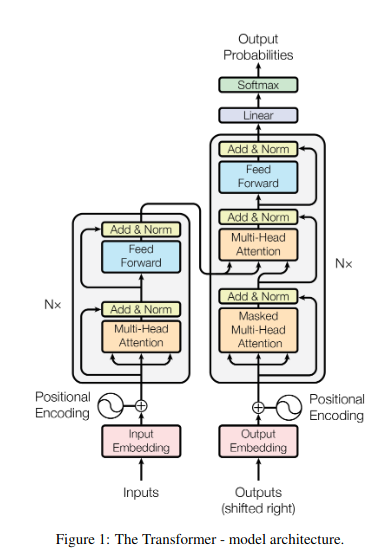
Encoder and Decoder Stacks
Encoder
The encoder is composed of N = 6 layers. Each layer has 2 sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple fully connected feed forward network. A Residual connection is made around each sub-layer which is added to the sublayer output and normalized.
Each Feed Forward Network is 2 Linear Transformations with ReLU Activation in between them.
Decoder
The decoder is also composed of a stack of 6 layers. We pass the encoder input to another sub-layer which performs multi-head attention.
Attention
A method for a model to learn about distant dependencies and to learn about related context in the input.
Can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. Output => weighted sum of the values, where the weight assigned to each value is computed by a function of the query with the corresponding key.
Scaled Dot-Product Attention
Input consists of queries and keys of dimension
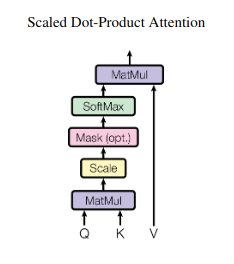
Two most commonly used attention functions are additive attention, and dot-product attention. Usually a dot-product attention is better and much faster in practice, due to implementing it in highly optimized matrix multiplication code.
However additive attention outperforms dot-product attention for larger values of
Multi-Head Attention
Instead of performing a single attention function, we do it h times in different subspaces, allowing the model to attend to different positions
Uses multi-head attention in three different ways:
- In "encoder-decoder attention" layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder. This allows every position in the decoder to attend over all positions in input sequence.
- The encoder contains self-attention layers. Each position in the encoder can attend to all the positions in the previous layer
- In the decoder, we have self attention layers, which attends to every previous word. We prevent the upcoming words to interfere by masking them
Positional Encoding
As there is no recurrence nor convolution, we need positional encodings to describe the order of the sequence. They are basically embeddings of the same size as our input and are summed with the input at the beginning of encoder and decoder stacks
Unsupervised Learning as Pre-training
There have been approaches where unsupervised learning was used with RNNs to understand language. [@daiSemisupervisedSequenceLearning2015] proposed two approaches with RNNs. The first approach is to predict the next token in sequence. The second approach is to use an AE based approach.
However, with the advent of Transformers, they were used as core model architectures for this task.
GPT
GPT - Generative Pre-trained Transformers
[@radfordImprovingLanguageUnderstanding2018] demonstrates the effectiveness of Generative Pre-Training in downstream tasks. Their hypothesis is that learning good representations in an unsupervised manner could boost the performance for downstream tasks irrespective of the availability of labelled data. The intuition could be that using pre-trained word embeddings gives a performance increase in the downstream tasks. So if we can somehow make a pretrained model which has language level information present already, it could give rise to increased performance in downstream tasks.
The issues with leveraging more than word-level information from unlabeled-text,
- What should be the objective function for the model to optimize, so that the learned representations are useful for downstream tasks?
- How to transfer the learned representations to the downstream task?
The authors used the objective of maximizing the probability of the next token given all the previous tokens (Next Token Prediction).
Supervised Fine Tuning is used to transfer the learned representations. Basically, it adds a linear layer instead of the next token prediction head and uses the objective for the down stream task to train all the parameters.
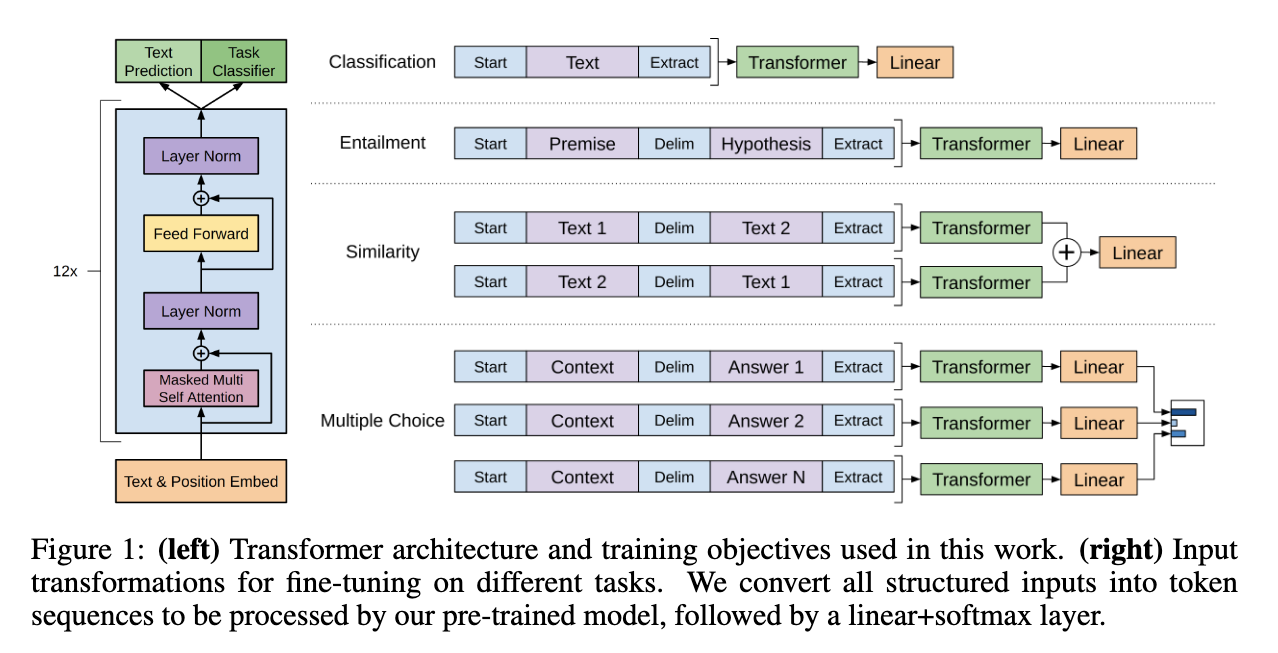
(Image taken from https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf)
The model uses the decoder from the Transformer as it's architecture. Based on the downstream task, the input is modified before finetuning.
BERT
BERT - Bidirectional Encoder Representations from Transformers.
Issues with GPT
- Models the language in a uni-directonal manner (left-to-right), which is sub-optimal for sentence level tasks like Question Answering
To overcome this, BERT uses Masked language Modelling as the pre-training objective. Basically a random set of tokens are masked and the objective is to predict it. In Literature, it is called as Cloze task. The objective is to just predict the masked words and not to reconstruct the entire input. The authors masked 15% of all the tokens. To mask a token, the authors replace it with [MASK] token . However, the downstream tasks don't have a [MASK] token. Thus, they make sure to leave it unchanged 10 percent of time or replace with a random token 10% of the time.
The first token for every input sequence is always a [CLS] token, whose final state would be used as the sentence representation for classification tasks. To allow for representing both pairs of sentences and single sentences, the pairs are concatenated into a single sentence with a [SEP] token. Aside from that, each token will have an embedding attached to it, indicating whether it belongs to sentence A or B.
Aside from Masked Language Modelling, there is also another pretraining task. It is a binarized next sentence prediction task. Basically given A and B sentences, based on the CLS token final state, classify whether B is the next sentence or not.
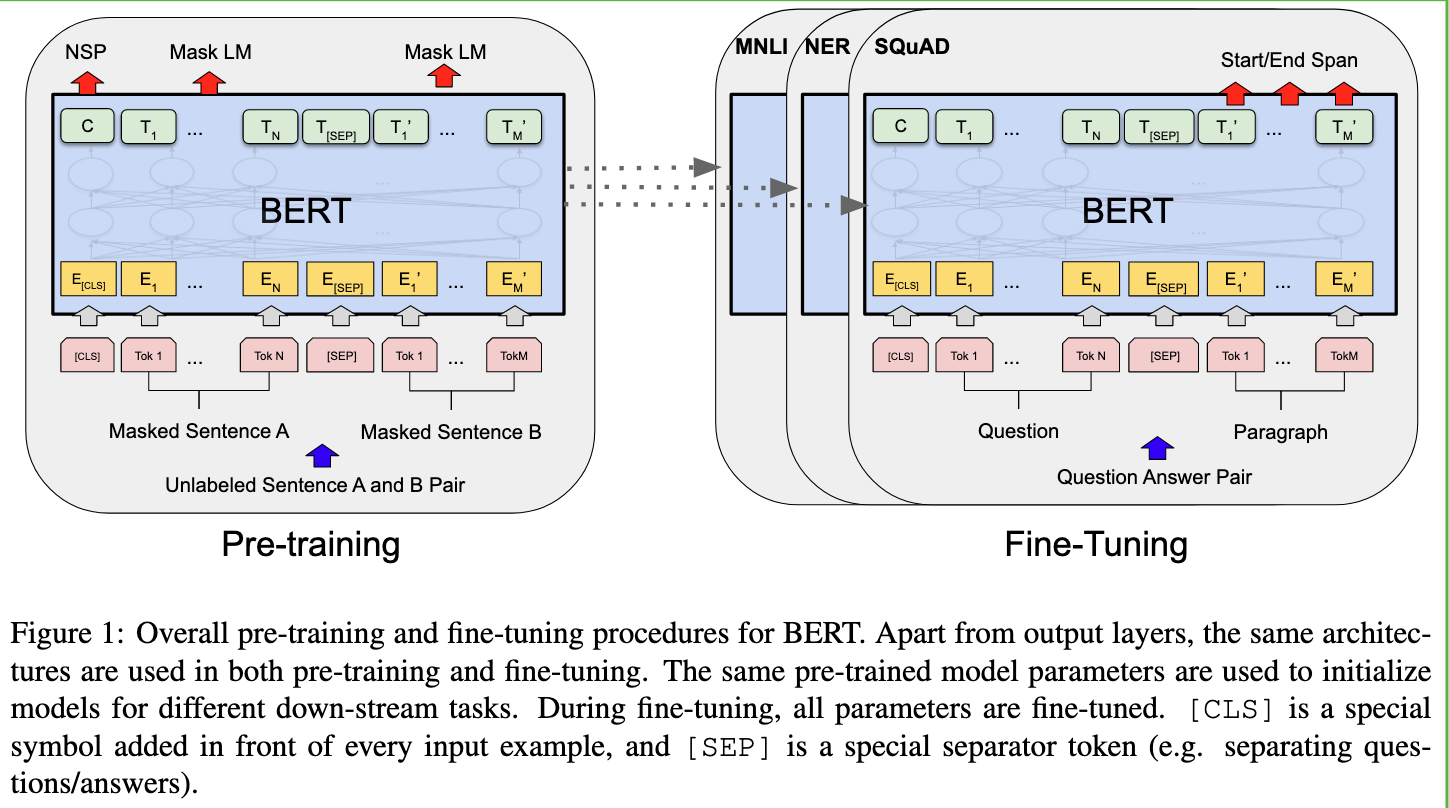
(Image taken from [@devlinBERTPretrainingDeep2019])
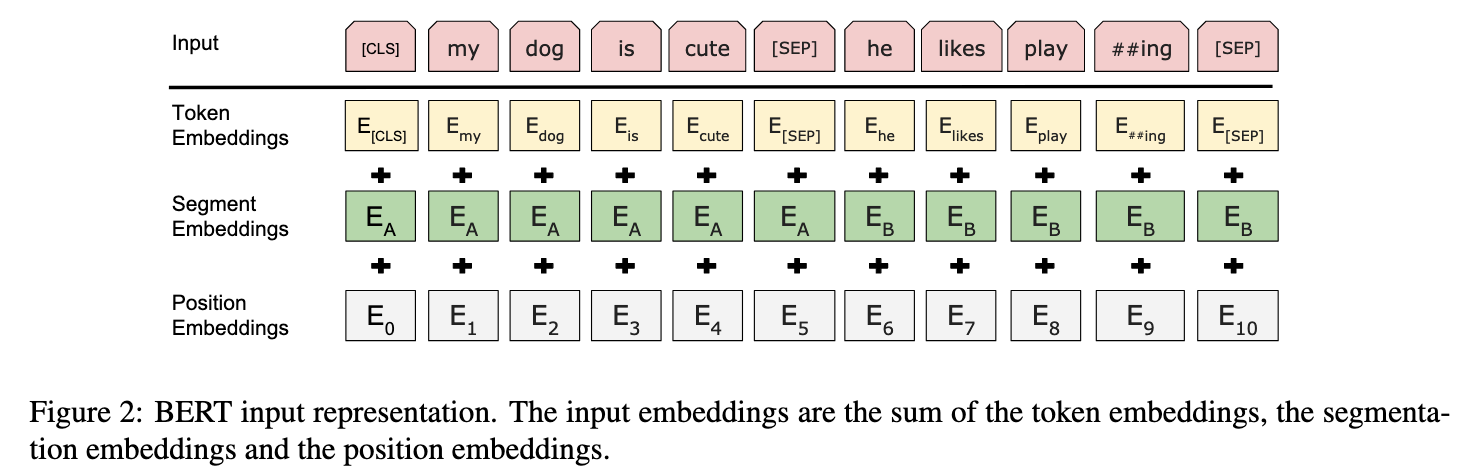
(Image taken from [@devlinBERTPretrainingDeep2019])
Finetuning is done with the task-specific objective. The representations are then sent to task-specific output layer.
References
[1]
D. Bahdanau, K. Cho, and Y. Bengio, “Neural Machine Translation by Jointly Learning to Align and Translate,” May 19, 2016, arXiv: arXiv:1409.0473. doi: 10.48550/arXiv.1409.0473.
[2]
A. Vaswani et al., “Attention Is All You Need,” Aug. 02, 2023, arXiv: arXiv:1706.03762. doi: 10.48550/arXiv.1706.03762.
[3]
A. M. Dai and Q. V. Le, “Semi-supervised Sequence Learning,” Nov. 04, 2015, arXiv: arXiv:1511.01432. doi: 10.48550/arXiv.1511.01432.
[4]
A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving language understanding by generative pre-training,” 2018, Accessed: Oct. 15, 2025. [Online]. Available: https://www.mikecaptain.com/resources/pdf/GPT-1.pdf
[5]
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” May 24, 2019, arXiv: arXiv:1810.04805. doi: 10.48550/arXiv.1810.04805.