Word Embeddings to Sentence Embeddings
Word Embeddings - A way to represent words as vectors so that we can give it to ML models.
Naive Attempt - Represent words as One-Hot Encoded Vectors
Issues - Creates a huge, sparse matrix that don't capture any form of semantic similarity.
Statistical Method - Represent words as value based on the frequency in which they appear in their respective documents. Calculated as a product of the respective Term Frequency and Inverse Document Frequency Values.
This could work well for tasks like information retrieval but it won't work for any tasks that involves some form of semantics, as it doesn't represent any form of semantic information.
Word2Vec
Introduced in [1]
There are two version of it,
- Continuous Bag-of-Words Model
- Uses a Log-Linear Classifier with 4 future words and 4 previous words as inputs to predict the current word
- Continuous Skip-gram Model
- Instead of predicting the current word based on context, use the current word as input to predict words within a certain range before and after the current word.
- Gives Less Weight to the distant words by sampling less from those words in the training examples
- However instead of trying to predict the word as we need to project the output of the softmax into the vocabulary matrix, i.e we need to predict a probability for each word. This is just too compute-intensive, we can try to modify it into a simpler task - Classify whether two words are neighbours or not? This technique is called Negative Sampling.
Training Process of the Skipgram Model
- Create 2 matrices - Embedding Matrix and Context Matrix of dimensions Embedding Size * Vocab Size.
- After that take a word
and their corresponding neighbour and samples which are not neighbours . Take the value of from the embedding matrix and the other values from context matrix. - Take the dot product of the
vector with the others and then get the sigmoid of it. - Use Negative Log Likelihood and use it update the model params.
- This ends up maximizing the positive sample probs and minimizing the negative sample probabilities, similar to Contrastive Loss.
GloVe - Global Vectors for Word Representation
Introduced in [2]
Word2Vec - A great embedding to represent local context information, but how do you insert global context with respect to the whole document.
Get the idea of pairing words with their neighbors from Word2Vec and have a model that calculates some sort of Global Context.
Basically, GloVe trains a model to predict the probability of co-occurence of two given words.
Given a word
To make sure very frequent pairs don't dominate the training a weighted function is used to give less weight to common pairs
The Math Behind getting to the Least Squares Objective
Starting with the ratio of Probabilities of word pairs
So given the word vectors of the three words, the output should be the ratio of the probabilities
As we need the word vectors to exist linear space, we could say the difference between
To make sure we get a scalar from the word vectors, we make the LHS a scalar by taking their dot product.
As it is symmetrical with respect to
That last line is just a complex way of saying we need a function F that converts addition w.r.t to word vectors into multiplication and subtraction to division.
So we need F such that
One such function is the exponential function,
Adding bias terms and shifting it into a cost function for Least Squares we get
where
The authors used the following for
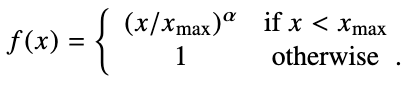
(Image taken from [2])
For the model they just used a log-bilinear model to train.
FastText
Introduced in [3]
The earlier approaches give a distinct representation to each word, however this ignores the morphology of words. This approach isn't extensible to new words as well.
The authors propose a skipgram model where each word is represented by a bag of character n-grams. The vector representation for a word is just the sum of the representation of the character n-grams
For example, the word where is represented by a character n-gram with <wh, whe, her, ere, re> and the also learn the representation of the word itself, so we add <where> to the bag.
In practice, all the n-grams for n greater or equal to 3 and smaller than 7 is used. The optimal choice for n depends on the task and language. A hash function is used that maps the n-grams to integers in 1 to K.
The score function between a word and it's context vector is simply the summation of the dot product of the character n-gram vectors.
ELMo - Embeddings from Language Models
Introduced in [4]
The meanings of words heavily depend on the context but the earlier approaches ignores the contextual dependence.
The core idea is to use the learnt representations from a Language Model. Easch token's representation is a function of the entire input sequence.
The representations are a linear function of the internal states of the language model. This allows the model to use different levels of context(word-level, sentence-level) learnt by the language model.
The authors used a bidirectional LSTM based language model.
ELMo is a task-specific representation, meaning that they are finetuned for a specific task.The weighting given to the specific layer representation of the language model is specific to the task. When training the ELMo representation, the language model's weights are freezed and the token representation concatenated with ELMo representation.
The authors found that it is better to add dropout and add a regularizing term
Sentence-BERT
Introduced in [5]
After the introduction of Transformers, GPTs and BERTs (RNNs to GPT and BERT) based architectures were used for most NLP tasks.
Sentence-BERT is a modification to BERT that allows the model to create semantically meaningful embeddings for sentences.
To get a fixed size output from BERT for sentences, the authors add a pooling operation to the output. They try three pooling strategies
- Output of the
[CLS]token - Computing the mean of all output vectors
- Max of the output vectors
To fine-tune the embeddings so that they are semantically meaningful, they create siamese and triplet networks based of BERT. Siamese and Triplet Networks work on the principle of Contrastive/Triplet Loss. Basically their core idea is to pull samples which are similar together and push those which aren't.
The authors experiment with three different objective functions. The objective functions used depends on the available training data.
- Classification Objective Function
- Concatenate the sentence embeddings
with element-wise difference and multiply it with a weight matrix and then pass it into a softmax. - Optimize using the cross entropy loss.
- Concatenate the sentence embeddings
- Regression Objective Function
- Calculate Cosine Similarity and then use MSE loss
- Triplet Objective Function
- Uses the Triplet Loss
- Given an anchor sentence
, a positive sentence and a negative sentence ,goal is to make the distance between and is smaller than the distance between and .
The authors found that using the MEAN strategy works the best. They also found that the element-wise difference vector which is concatenated is important to the classifier.
References
[1]
T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient Estimation of Word Representations in Vector Space,” Sep. 07, 2013, arXiv: arXiv:1301.3781. doi: 10.48550/arXiv.1301.3781.
[2]
J. Pennington, R. Socher, and C. Manning, “Glove: Global Vectors for Word Representation,” in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar: Association for Computational Linguistics, 2014, pp. 1532–1543. doi: 10.3115/v1/D14-1162.
[3]
P. Bojanowski, E. Grave, A. Joulin, and T. Mikolov, “Enriching Word Vectors with Subword Information,” Jun. 19, 2017, arXiv: arXiv:1607.04606. doi: 10.48550/arXiv.1607.04606.
[4]
M. E. Peters et al., “Deep contextualized word representations,” Mar. 22, 2018, arXiv: arXiv:1802.05365. doi: 10.48550/arXiv.1802.05365.
[5]
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks,” Aug. 27, 2019, arXiv: arXiv:1908.10084. doi: 10.48550/arXiv.1908.10084.